Price Per Token Falls. Total Spend Doesn't.
Basile Senesi
CRO

The benchmark wars are over. The price war just started. And the enterprises with the wrong architecture are going to learn that lesson on a budget call.
In June 2026, Microsoft will cancel most internal Claude Code licenses, six months after launching the pilot. The official line is consolidation around Copilot. The real story, confirmed by multiple post-mortems, is that token-based billing burned through annual budgets in months. Around the same time, Uber's CTO told the company its entire 2026 AI budget was exhausted in four months, with individual engineers running $500 to $2,000 a month in inference costs and monthly AI tool usage hitting 95% of engineering.
These are not procurement stories. They are architecture stories. Enterprises that bet on a single frontier lab and unbounded token consumption are discovering, quarter by quarter, that the bill is real.
The enterprise AI winners of the next 18 months will be vertical, model-agnostic, agentic, and auditable. Token pricing, accuracy, security, and workflow depth are not separate conversations. They collapse into one architecture decision every CIO is now being forced to make.
The subsidy era is ending in real time
Frontier labs subsidized inference to win enterprise lock-in. That phase is over.
AI software prices are up 20% to 37% in recent months. GitHub shifted Copilot from request-based to usage-based billing on June 1, 2026. Anthropic stripped bundled tokens from enterprise seats. The list price often does not move. The repricing happens through the tokenizer, where most buyers do not look.
Token economics are structurally misaligned with the buyer. Lab revenue is a derivative of customer token consumption. That means the supplier is incentivized to be inefficient with your context window. The bigger the token blob it stuffs into your job, the more you pay, and often the worse the answer gets.
Flagship pricing now sits at $25 to $30 per million output tokens for Opus and GPT-5.5, with Gemini 3.x Pro at $12 and Gemini 3.5 Flash at roughly $9. Meanwhile, per-token cost has collapsed roughly 1,000x, with Epoch AI measuring 40x annual declines on PhD-level reasoning benchmarks and up to 900x on narrow tasks. Enterprise generative AI spend has grown 320% over the same window.
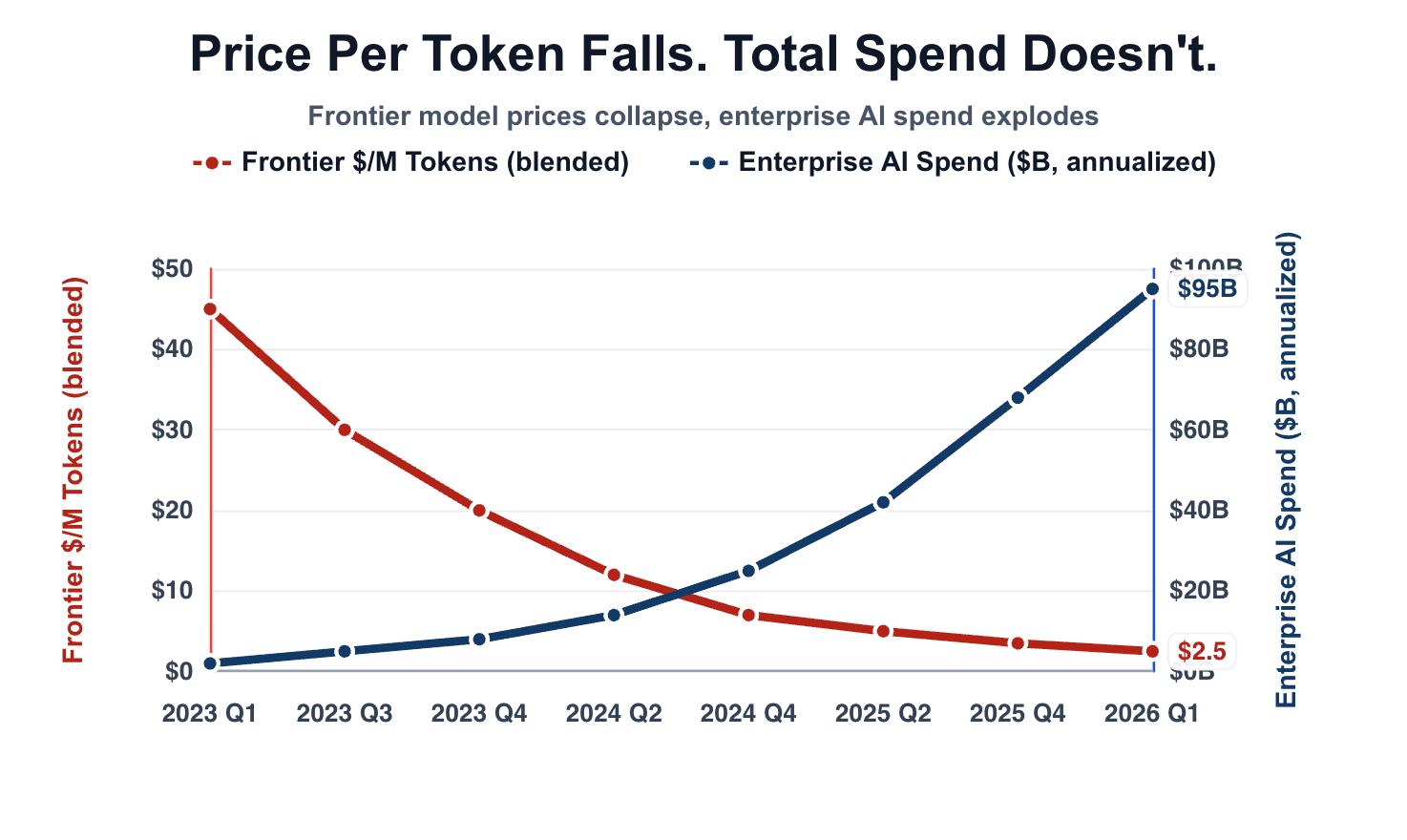
That is Jevons paradox showing up inside enterprises. Cheaper compute drives more usage. Adoption is working exactly as advertised, and the budget is what cracks.
The question is no longer which model is smartest. It is which architecture stays solvent when adoption actually works.
Cost-per-task replaces benchmark bragging rights
The metric that matters has moved from raw capability to economic viability per task. Pareto frontier framing wins. Cost-per-performance, not peak performance, decides what ships at scale.
A concrete example. Independent testing of Gemini 3 Flash against Gemini 2.5 Pro found Flash delivering better quality, 2.4x lower latency, and roughly 3x lower cost on real workloads. Other comparisons put Flash at ~92% of GPT-5.5-class quality at a fraction of the token cost, with inference speeds of 289 tokens per second versus 67 to 71 on the heavyweights.
Anthropic is collapsing its own premium tier. Sonnet 4.6 at $3 per million input tokens is matching or beating Opus 4.6 at $15 on financial analysis and office tasks. The labs are signaling, with their own pricing, that the cheap model is good enough for most of the work. GPT-4 level quality is now roughly 500x cheaper than it was in 2023. The cost curve is collapsing on the model layer.
The same pattern shows up on the SWE-rebench leaderboard, which logs cost-per-issue alongside solve rate on real GitHub issues. The top tier of coding agents clusters between 60% and 65% resolved, while cost-per-issue ranges from $0.14 on Step-3.5-Flash to over $1.10 on Claude Opus 4.6 — an 8x spread for a five-point performance gap. Buying the most expensive model on the leaderboard is mostly buying a procurement story, not an accuracy story.
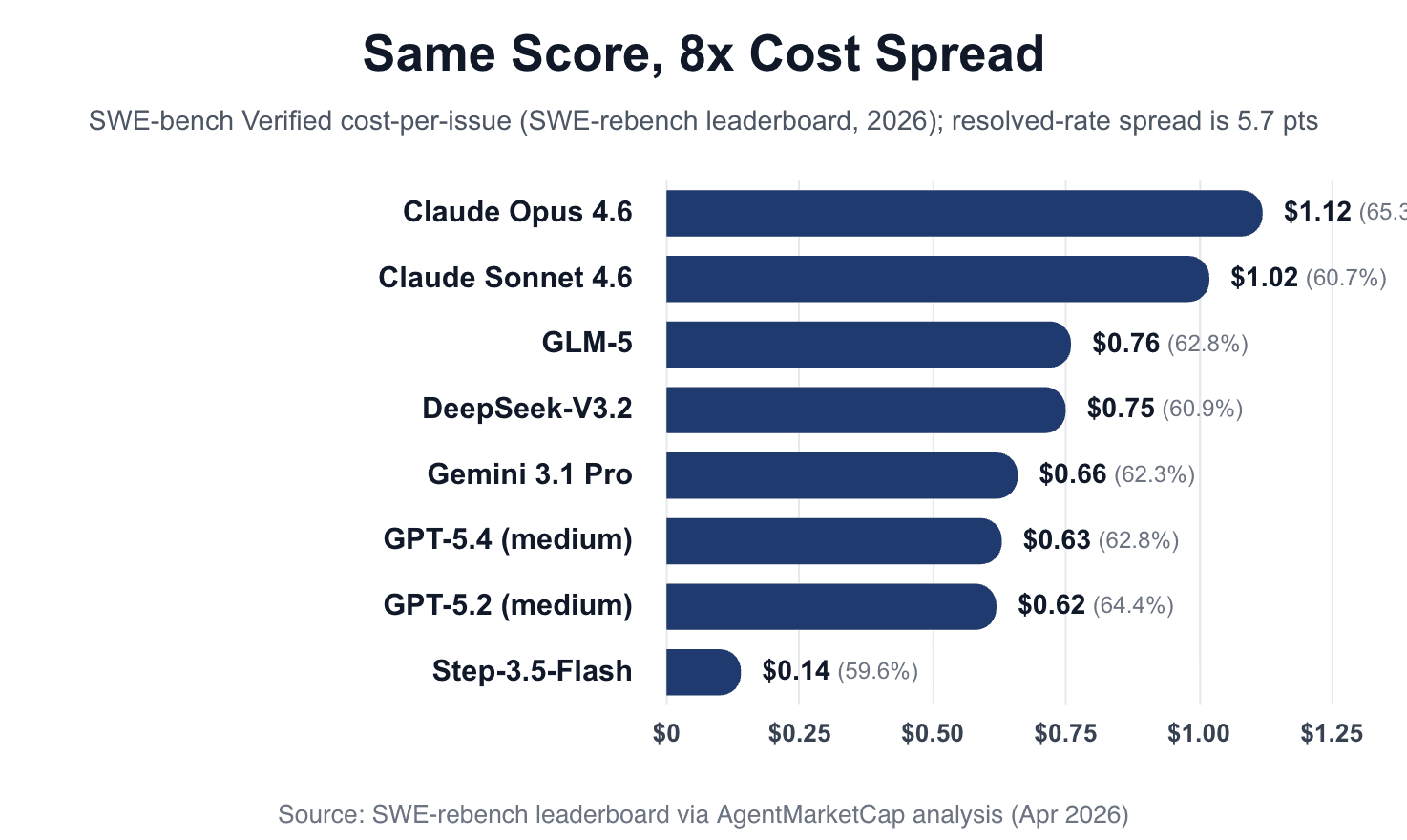
For agentic workloads, where one user request fans out into dozens of tool calls, cost-per-task is the only metric that makes the unit economics work. Google's vertical integration on custom silicon and owned data centers is structurally enabling this. Labs without that stack will struggle to match.
Heuristic for buyers. The best model for an enterprise workflow is the one that is smart enough and economically scalable. Anything else is a demo budget waiting to detonate.
Single-vendor architectures are now a risk register item
Three structural risks come with betting the firm on one lab.
Token repricing risk.
The lab adjusts pricing or rate limits. Your unit economics break. We have already watched this play out at Microsoft and Uber inside one fiscal cycle.
Capability drift risk.
A model upgrade changes formatting, refuses tasks it used to handle, or hallucinates differently. Production workflows regress without anyone deploying a new line of code. The vendor's roadmap is your incident report.
Encroachment risk.
Frontier labs are moving up the stack from infrastructure into applications. OpenAI Frontier and Anthropic Managed Agents both shipped enterprise platforms in early 2026. Every SaaS built on one lab's API is now a competitor of that lab. Sharing decision-grade data without filters with a single provider compounds the problem. You are training the system that will eventually compete with your business.
| Quarter | OpenAI | Anthropic | |
|---|---|---|---|
| 2023 Q3 | ChatGPT Enterprise (Aug 2023) | — | — |
| 2023 Q4 | GPTs & Assistants API (Nov 2023) | — | — |
| 2024 Q3 | — | Claude for Enterprise (Sep 2024) | — |
| 2024 Q4 | — | Computer Use (Oct 2024); Model Context Protocol (Nov 2024) | — |
| 2025 Q1 | Operator (Jan 2025) | — | — |
| 2025 Q2 | — | — | Agentsspace GA (Apr 2025) |
| 2025 Q4 | — | — | Gemini Enterprise (Oct 2025) |
| 2026 Q1 | Frontier Platform | Managed Agents | — |
| 2026 Q2 | — | — | Gemini Enterprise Agent Platform (Apr 2026) |
A serious architecture has three things. An abstraction layer above model APIs. Task-level evals so you actually know which model is winning where. And routing logic that lets you swap providers without rewriting the application. Cost arbitrage is a real lever. The same task can vary 10x in price across providers at similar quality. Multi-model is the only way to capture that without a rewrite.
Heuristic for CIOs. If a workflow runs on one model and you cannot swap it in a week, that workflow is on the risk register.
Vertical beats horizontal. The math has not changed.
Horizontal copilots are converging. Vertical, workflow-deep AI is where defensibility lives.
The TAM is the labor line, not the software line. McKinsey Global Institute estimates gen AI alone could deliver $2.6T to $4.4T in annual value, concentrated in a handful of high-margin, labor-intensive industries. Foundation Capital sizes Services-as-Software at $4.6T, roughly 10x the global software market. Bessemer's vertical AI thesis lands at the same place. Different framings, same conclusion. The prize is the labor line, not the software line.
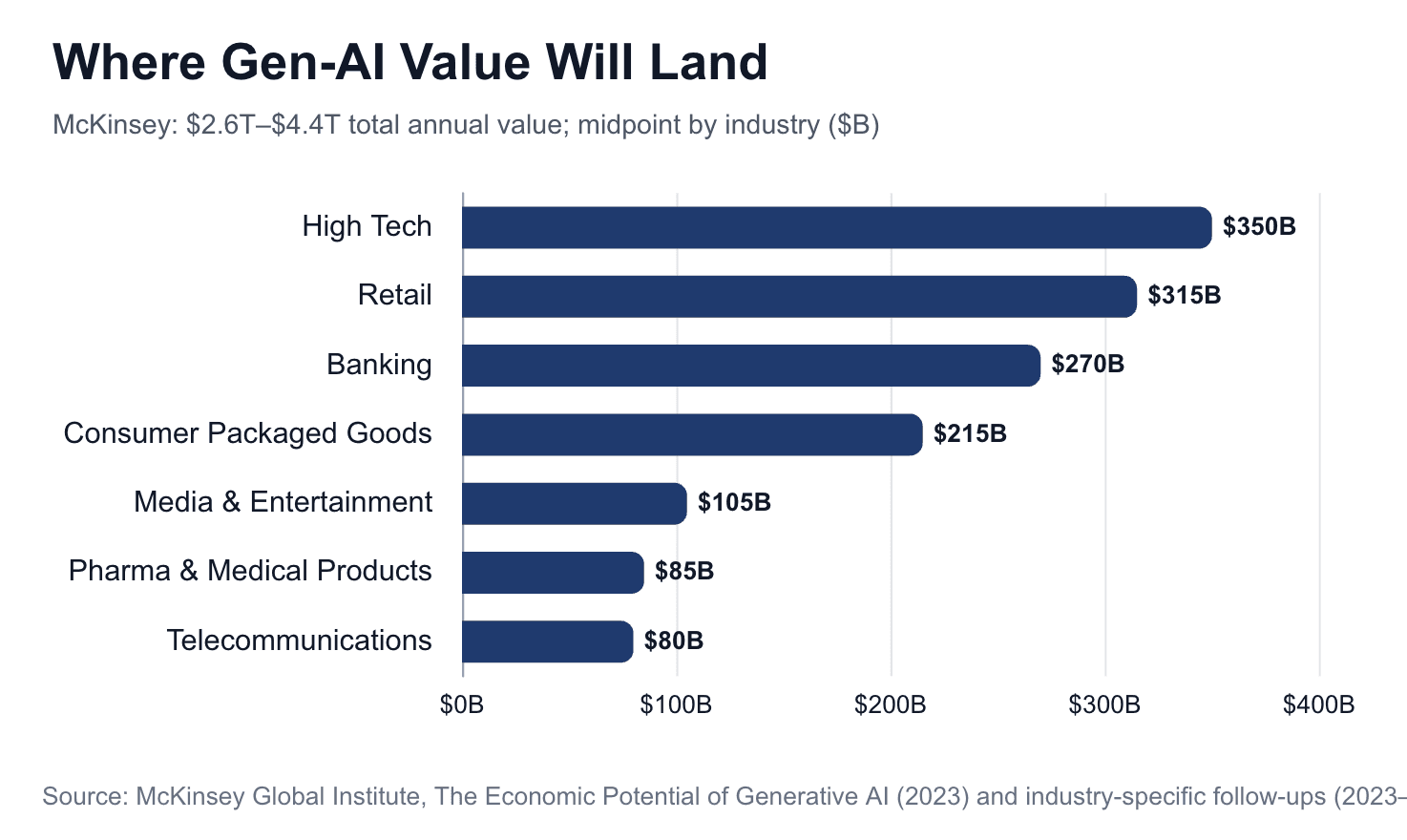
Three things vertical AI does that horizontal copilots structurally cannot.
Domain-specific evals tied to real outputs. A closed deal, a filed memo, an approved credit decision. Workflow integration with the systems of record that already run the business. And regulatory and audit posture baked in from day one. Generic chat-with-your-docs is a feature. A diligence agent that produces an auditable databook with cell-level citations is a product.
Regulatory moats are real and asymmetric. SaaS alone has no regulatory moat. Legal work has bar requirements. Capital allocation requires regulated capital. Healthcare has HIPAA. Banking has supervision. Vertical AI in regulated industries inherits those moats. Horizontal copilots do not. The lesson from prior platform shifts is consistent. The application layer captures most of the value. There is no reason to expect this one to be different.
Vertical workflow depth without the right data is still a wrapper. The real moat sits one layer deeper.
Institutional knowledge is the moat the labs cannot copy
Foundation models are trained on the public internet. The expensive, decision-grade data inside the enterprise is invisible to them and structurally always will be.
A mid-tier model with full institutional context outperforms a frontier model running blind on the same task. This is now demonstrable, not theoretical. Consumer platforms compounded behavioral signal for two decades. Netflix, Meta, Google. Enterprises never built that loop because their decisions are multiplayer negotiations across sales, finance, legal, and ops, not single clicks. AI finally makes that reasoning observable. Foundation Capital calls this the compounding asset enterprise software never had, and the framing fits.
The highest-leverage AI investment in a typical enterprise is not a license. It is the data plumbing, the indexing, and the governance that lets every internal AI workflow tap the firm's history. Treat data as infrastructure. Fund it like infrastructure. Operate it like infrastructure.
The practical implication ties this back to Section 2. When you can route a task to a cheaper, faster model that still wins because it has your context, the token-pricing pressure stops being a cost problem. It becomes a margin advantage.
Heuristic for heads of AI. Inventory the top five datasets that would make every internal AI workflow ten times more useful if exposed correctly. Those are your infrastructure projects for the next four quarters.
Agentic without auditability is a regulatory time bomb
Security and accuracy are not nice-to-haves. They are the difference between scaling AI firmwide and getting shut down by your own risk function.
"Peak performance" for current agentic systems usually means full access to your compute, your machine, and as much of your data as possible. Unsandboxed computer use. That is fine for a demo and a business killer for a regulated firm.
Two failure modes are already showing up in production.
Indirect prompt injection. Every connected document becomes a potential attack vector. Simon Willison's lethal trifecta, private data, untrusted content, and the ability to externally communicate, is now a documented attack class with no general fix. A malicious cell in a vendor spreadsheet can exfiltrate firm data through an unguarded agent. The defense is architectural, not a prompt.
Opaque execution environments. Code that runs once and disappears in a Python sandbox cannot be reviewed by a compliance officer or replayed by a regulator. If your AI cannot show its work, your AI cannot ship in financial services.
Data privacy leaks are a business killer for regulated industries. Even when the leak does not happen, opacity is a sure way to have IT and compliance turn sour on AI adoption firmwide. The answer is deterministic, inspectable infrastructure. Cell-level provenance. Spreadsheet runtimes that retrace every number to its source. NIST AI Risk Management Framework-aligned controls. Sandboxed tool use with explicit data access scopes.
Enterprises that built on opaque agents in 2024 and 2025 will be retrofitting in 2026. The ones that built on auditable infrastructure will be expanding into new use cases while their peers are answering regulator questions.
Heuristic for risk officers. Demand cell-level provenance from any AI vendor producing financial or analytical output. If they cannot show the source of every number, they are not enterprise-ready.
The four-layer architecture that compounds
Pull the threads together into a portable mental model. Four layers, in order.
- Model routing. Multi-model abstraction with task-level evals. No key-man risk on any one lab. Cost-per-task as the routing signal.
- Vertical workflow depth. Domain schemas, regulatory posture, integration with systems of record. The product replaces a service. It does not augment a search box.
- Institutional knowledge. Indexed, governed access to the firm's own historical data. Treated as infrastructure, funded as infrastructure.
- Audit and provenance. Cell-level citations, deterministic runtimes, NIST-aligned controls, sandboxed tool use.
The compounding logic is straightforward. Layer 1 absorbs the price war and capability drift. Layer 2 captures the labor-line TAM. Layer 3 makes cheaper models outperform expensive ones for your specific work. Layer 4 is what lets all of it ship inside a regulated firm.
Buyers should evaluate every AI vendor on all four layers. Anything that can only check one or two is 2023 architecture wearing 2025 marketing.
What CIOs and CTOs should actually do this quarter
Five concrete moves, in priority order.
- Audit current vendor lock-in. Map every production AI workflow to its underlying model. Anything single-source goes on the risk register with a remediation owner and a date.
- Stand up a model-agnostic abstraction layer, even minimal. The cost of doing this later is much higher than the cost of doing it now. Add task-level evals so routing decisions are evidence-based, not vibes.
- Run a repricing stress test. Model what happens to unit economics if your top three vendors raise prices 30%, drop subsidies, or move to strict usage-based billing. If any single move breaks the P&L, you have a single-point-of-failure dressed up as a partnership.
- Inventory institutional knowledge. Pick the top five datasets that would meaningfully improve every internal AI workflow if properly exposed. Fund the data plumbing as infrastructure, not as a project.
- Demand cell-level provenance. From any AI vendor producing financial or analytical output. No source, no contract.
Bonus pilot. Run a vertical AI product against a horizontal copilot on the same workflow. Measure cycle time, error rate, reviewer trust, and cost-per-task. The gap will be obvious, in both directions.
Closing
The next 18 months sort the market into two camps.
Companies built on a single horizontal foundation, exposed to repricing, capability drift, security debt, and vendor encroachment. And companies built on multi-model, vertical, knowledge-rich, auditable architectures, compounding their data advantage every quarter.
Frontier labs are racing to build everything. Enterprises should be racing to build what only they can.
The model is not the moat. Your data, your workflows, and your audit trail are.
Continue reading


